

Qu’est-ce que le Machine Learning ?
Le machine learning ou apprentissage automatique est la science qui consiste à faire en sorte que les ordinateurs agissent sans être explicitement programmés. Au cours des dix dernières années, l’apprentissage automatique nous a permis l’essor de plusieurs domaines tels que les voitures autonomes, la reconnaissance de la parole, la recherche efficace sur le Web et la compréhension, considérablement améliorée, du génome humain.
Peut-on concevoir une machine ayant des capacités intellectuelles égales à celle du cerveau humain ? Depuis Blaise Pascal et Von Leibniz, nombreux sont les scientifiques et ingénieurs qui se sont posé cette même question.

Source : Pompe au net
Des écrivains célèbres comme Jules Verne, Frank Baum (magicien d’OZ), Mary Shelley (Frankenstein), George Lucas (Star Wars) ont imaginé des êtres artificiels ayant des comportements humains.
L’apprentissage automatique est l’une des branches les plus importantes de l’Intelligence Artificielle (IA). Les géants du secteur de la technologie, tels que Baidu et Google, ont dépensé entre 20 et 30 milliards de dollars dans le domaine de l’IA en 2016 : 90% dans la recherche et le développement, et 10% pour des acquisitions IA.
C’est aujourd’hui une véritable course aux brevets et à la propriété intellectuelle.
Rappelons cependant qu’il ne s’agit pas d’un domaine récent. Turing, Hebb, Samuel et Rosenblatt, parmi bien d’autres, ont pavé la route des récentes avancées.
Le Machine Learning : Quésaco ?
Les probabilités, la statistique et l’algèbre linéaire au service des données. C’est une convergence de moyens mis en œuvre pour modéliser un ensemble de données et découvrir une structure interne permettant d’effectuer les deux tâches principales : la régression et la classification. Tout processus de Machine Learning peut être décomposé en trois phases :
- Pré-traitement des données,
- Modélisation,
- Déploiement, maintenance.
Une fois les données nettoyées et structurées, elles peuvent être présentées aux algorithmes de machine learning.
Identifier le type de problème
Catégoriser par entrée
- Si les données sont étiquetées, il s’agit d’un problème d’apprentissage supervisé.
- Si elles ne le sont pas et qu’on est à la recherche d’une structure, il s’agit d’un problème d’apprentissage non supervisé.
Catégoriser par sortie
- Si la sortie est un nombre, c’est un problème de régression.
- Si la sortie est une classe, c’est un problème de classification.
- Si la sortie est un ensemble de groupes d’entrée, c’est un problème de clustering.
L’apprentissage des machines
Deux différents types d’apprentissage
Apprentissage supervisé
Phase d’apprentissage : Les données sont présentées en ayant été préalablement labellisées. Chaque entrée est associée à une valeur de sortie qui peut être numérique ou catégorique.
L’algorithme tente alors de trouver la règle permettant de relier l’entrée (x) à la sortie (y), c’est le modèle prédictif qui est construit.
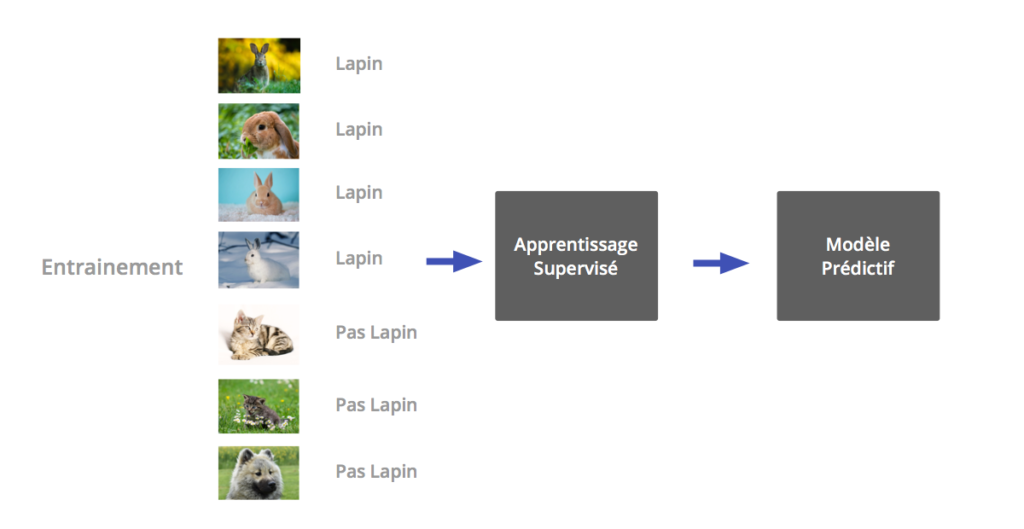
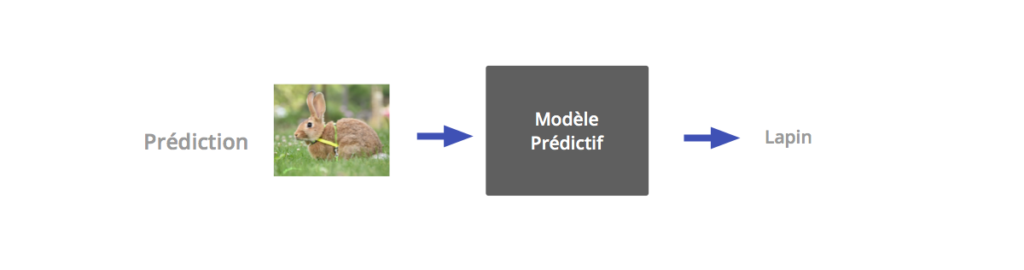
Phase de prédiction : On présente une nouvelle entrée au modèle, celui-ci est chargé de lui associer la sortie correcte.
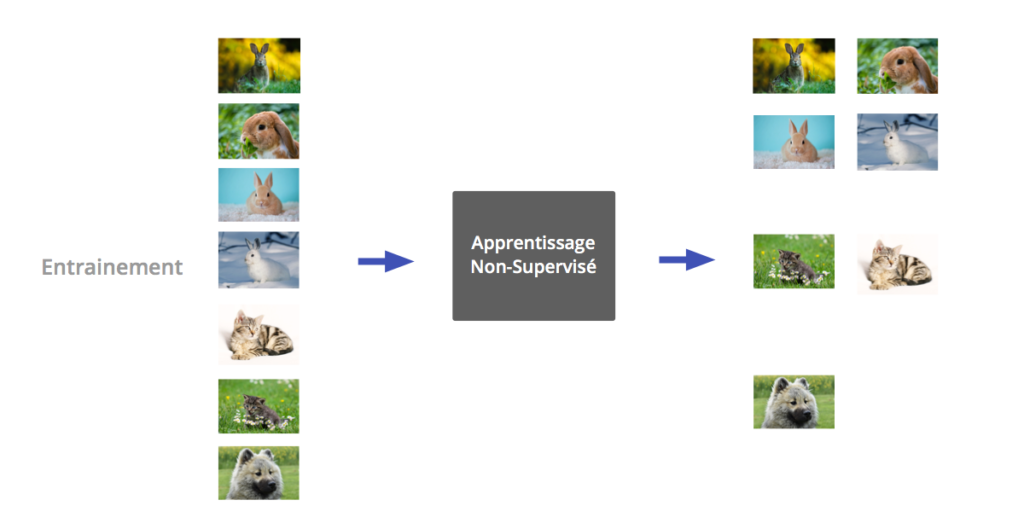
Apprentissage non supervisé
Dans de nombreuses situations, les données ne sont pas labellisées. L’apprentissage non supervisé permet alors d’y découvrir un découpage caché. C’est le clustering. Les données sont alors regroupées dans un certain nombre de clusters.
Algorithme d’apprentissage
Algorithmes d’apprentissage automatique couramment utilisés
| La régression linéaire | L’algorithme tente de trouver une relation linéaire entre l’entrée et la sortie numérique. |
| La régression logistique | Il s’agit d’un classifieur binaire construit sur un modèle linéaire associé à une sigmoïde. |
| Arbres de décision | Structure de type organigramme dans laquelle chaque nœud est un test sur un attribut et chaque branche représente le résultat du test. |
| Forêt aléatoire | C’est un ensemble d’arbres de décision dans lequel chaque arbre s’entraine sur une partie des données extraite de manière aléatoire. |
| Machines à vecteurs de support | Les données sont représentées dans un espace qui permet de les séparer par catégorie. Les nouvelles données sont alors placées dans ce même espace et sont alors catégorisées. |
| KNN (K nearest neignbourgs) | C’est l’algorithme des k plus proches voisins. C’est un apprentissage non supervisé et les données sont regroupées selon les similitudes qu’elles peuvent avoir les unes avec les autres. |
Comment les choisir ?
Maintenant que la nature du problème est bien identifiée, il est temps de sélectionner les algorithmes appropriés. De nombreuses considérations sont encore à prendre en compte comme :
Les limites du machine learning
La performance des algorithmes de Machine Learning n’est plus à prouver et ils sont aujourd’hui implémentés dans une multitude de process. L’arrivée du Big Data a cependant posé quelques soucis de performance au traditionnel mode d’apprentissage. Les données sont devenues trop volumineuses et complexes. L’extraction de caractéristiques (« feature extraction« ) est alors devenue une tâche complexe, nécessitant la présence d’un expert métier pour une sélection pertinente des caractéristiques.
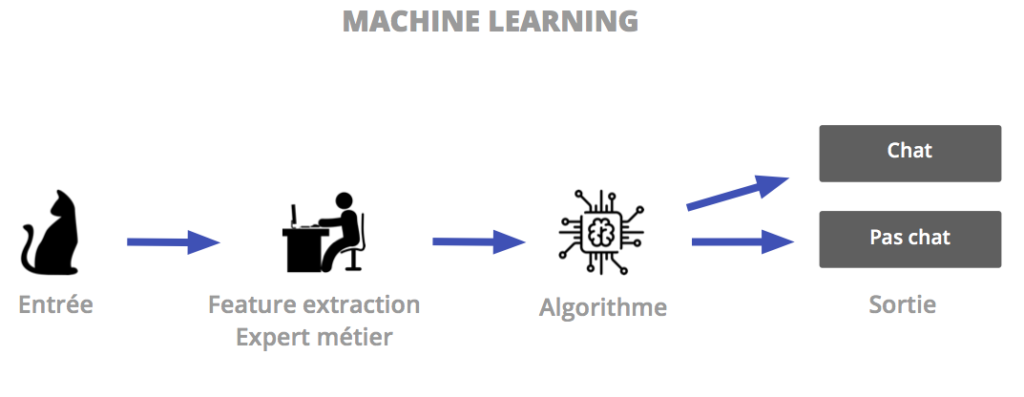
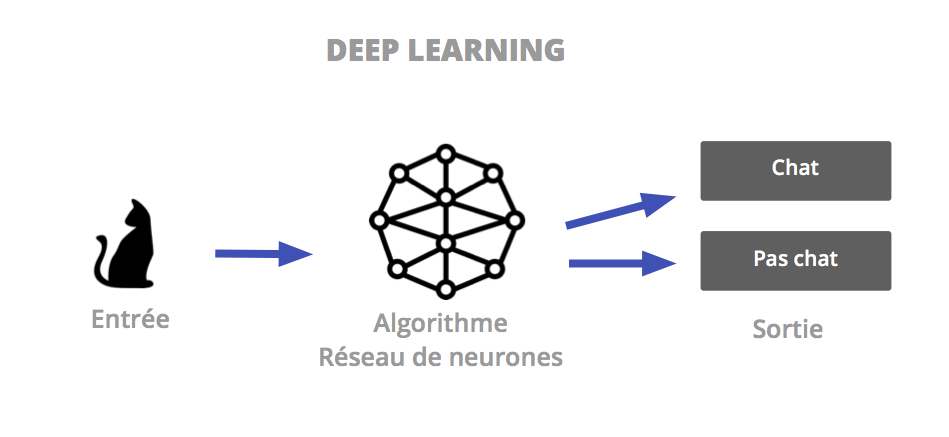
C’est ainsi que le Deep Learning s’est imposé ces dernières années comme une méthode phare de la Data Science. Le deep learning nous rapproche encore un peu plus du fonctionnement du cerveau humain et s’attaque aux domaines de la vision, du langage naturel, mais aussi de l’analyse de sentiments et de l’empathie.


